About Me
I am Head of AI at CONXAI Technologies, in Munich, Germany. My role involves developing deep AI tech with significant impact in the Architecture, Engineering and Construction (AEC) industry. I define the company's AI strategy and lead a talented team of ML Engineers implementing innovative AI solutions.
I did my Postdoctoral Research with Michael Black at the Max Planck Institute for Intelligent Systems in Tübingen, Germany. I received my PhD in Computer Science at Georgia Tech, advised by Devi Parikh.
I have also been fortunate to spend summers at Toyota Technological Institute in Chicago (TTIC), Facebook AI Research (FAIR), Curai Health and Indiana University's Dept. of Psychological and Brain Sciences.
Arjun Chandrasekaran
Head of AICONXAI Technologies
Munich, Germany.
Email: arjun.chandrasekaran@conxai.com
Google Scholar
Curriculum Vitae
Research
I am interested in multi-modal machine-learning problems in computer vision and natural language processing.
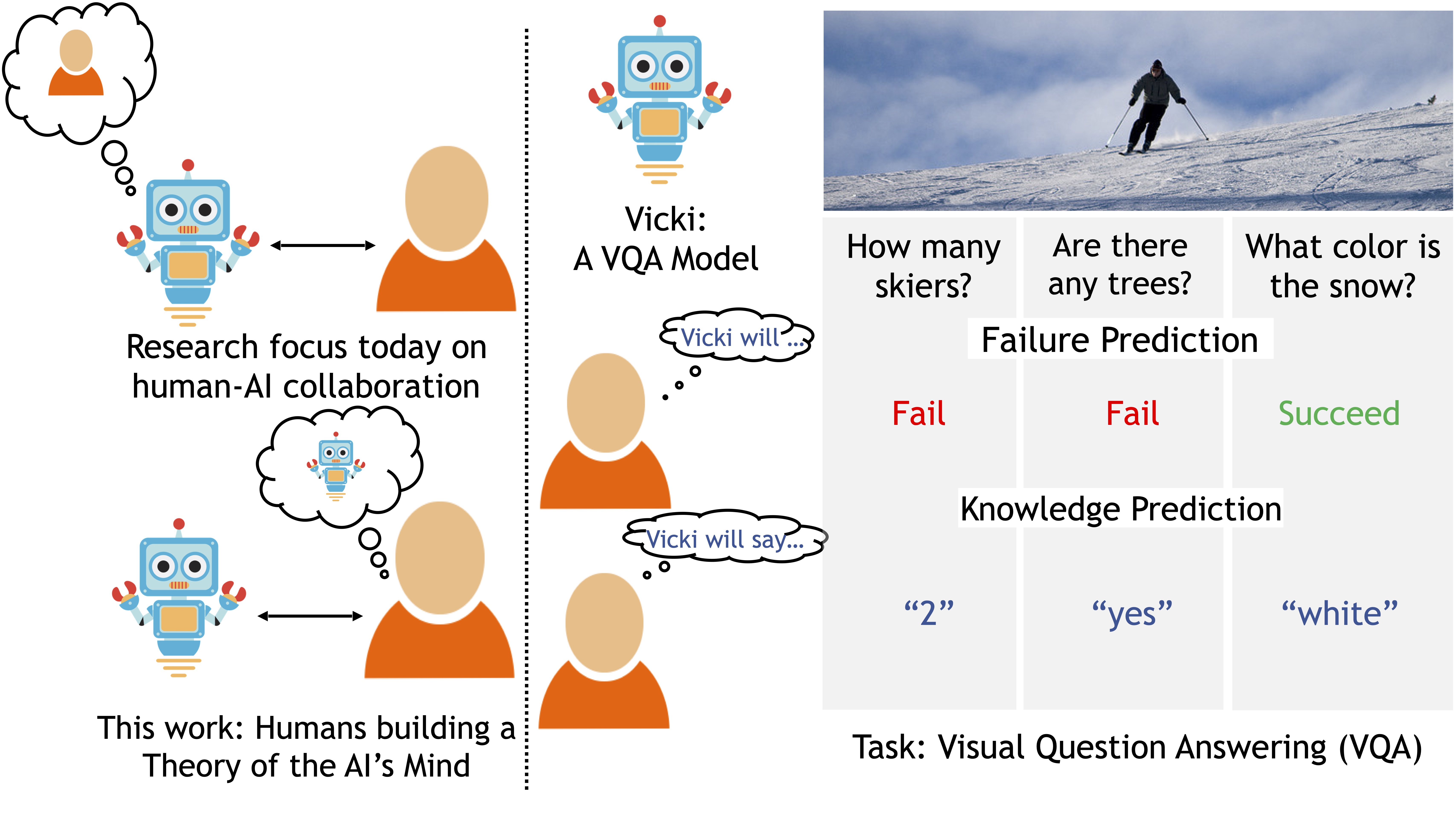
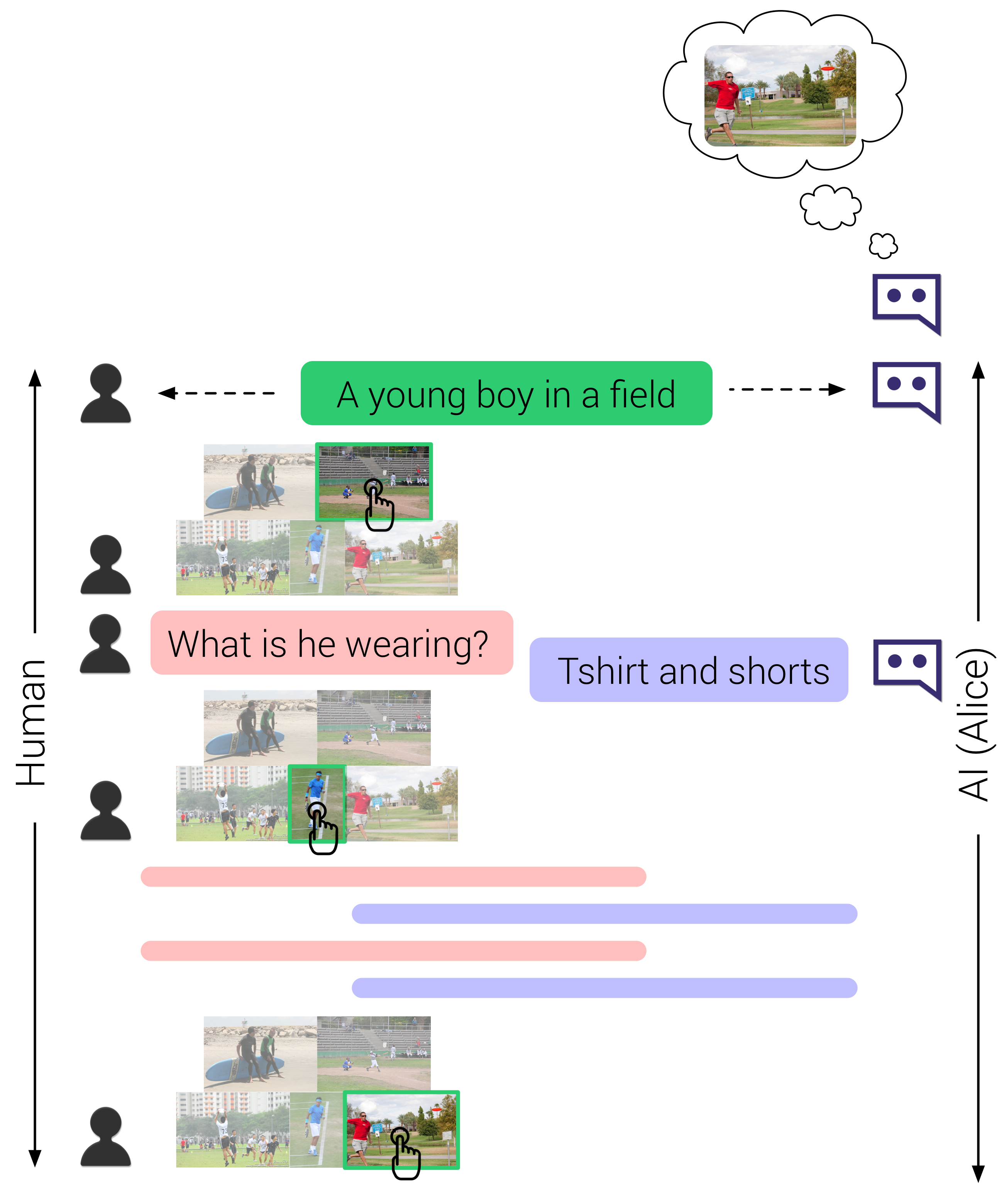
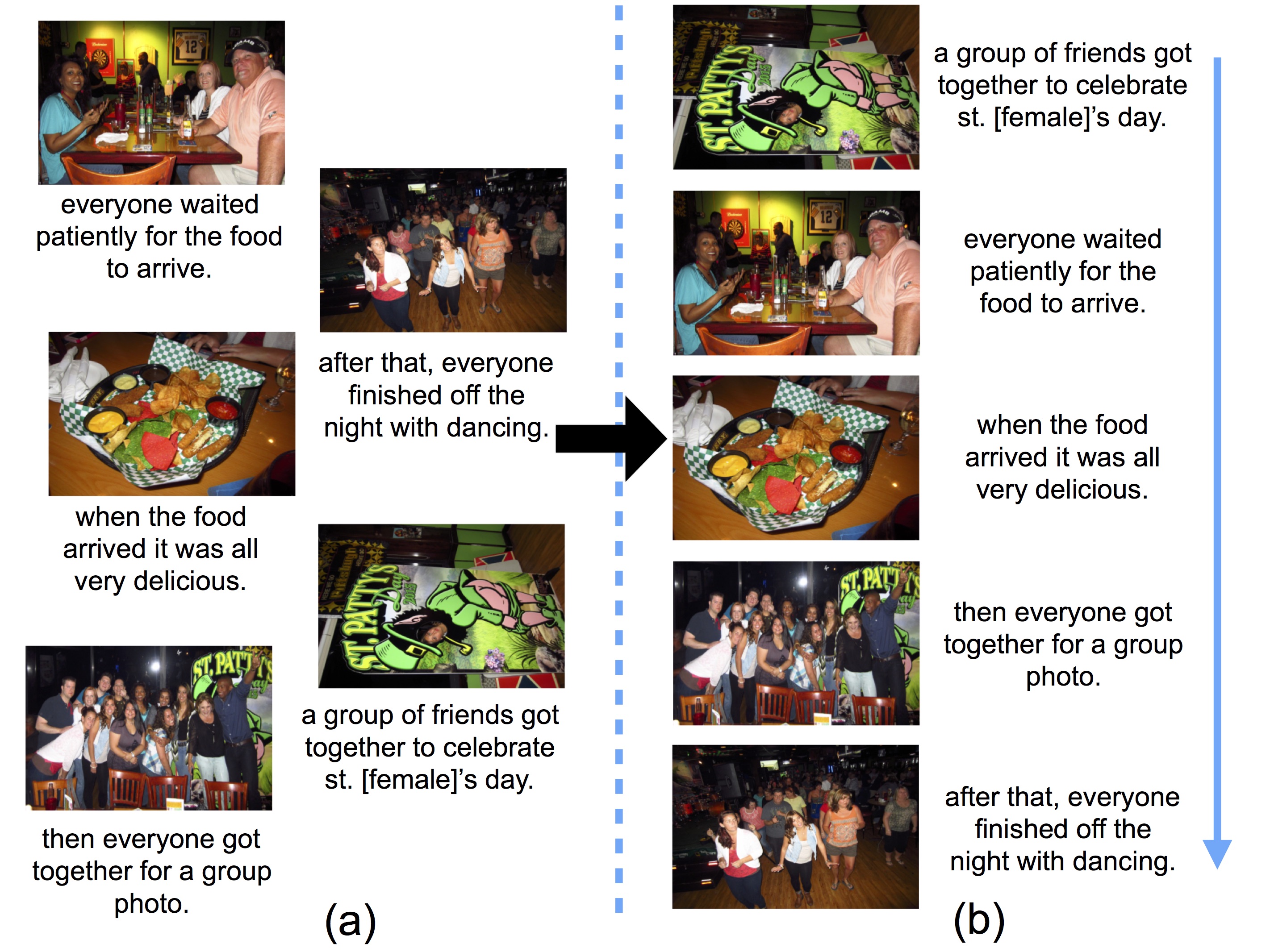
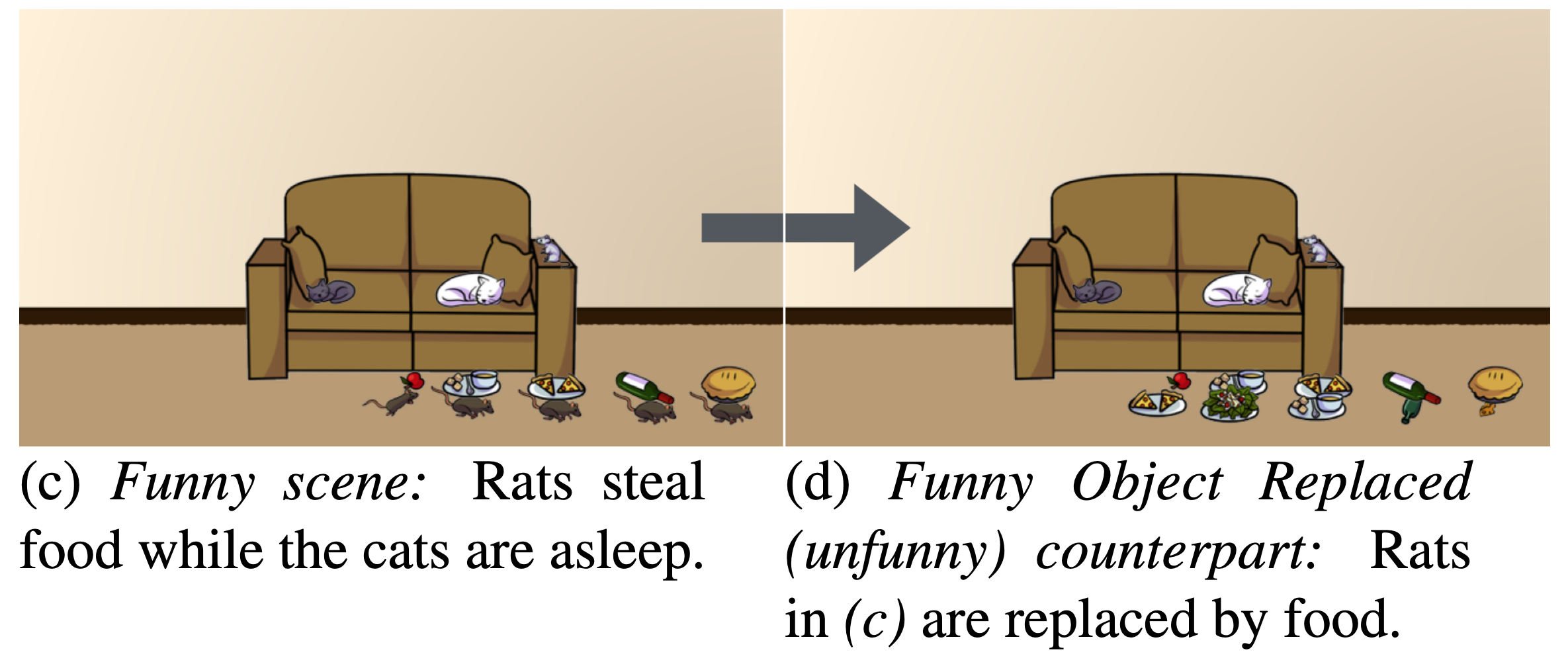
In the past, I worked on human action understanding in 3D, computational models for embodied human interactions, and specific aspects of human interactions such as humor and narrative. I also worked on understanding human-AI interactions with the goal of creating better human-AI teams.
My work and interests span the areas of computer vision, natural language processing, machine learning, crowdsourcing and cognitive science.